
Security teams do not struggle with visibility because they lack tools. They struggle because the tools rarely speak the same language, and when they do, nobody trusts the output enough to act quickly.
CrowdStrike’s NG-SIEM enters that conversation with a promise of unifying endpoint, identity and cloud telemetry under one roof. It extends the Falcon platform into detection and response across broader data sets. The appeal is obvious. Less swivel-chair analysis. Faster triage. Tighter alignment between prevention and investigation.
But implementation is rarely straightforward. A poorly planned rollout can create noise at scale. That defeats the point.
The following reflections draw on field experience and hard lessons learned from complex SIEM migrations and consolidations. These are not theoretical notes. They are patterns observed repeatedly across regulated industries, mid-sized enterprises and distributed global teams.
Start with the Operating Model, Not the Tool
Too many projects begin with a feature comparison. Storage tiers. Query performance. Connector libraries. Those matter, but they sit downstream of a more uncomfortable question.
How does the organisation actually respond to incidents?
Some teams escalate everything through a central SOC. Others push ownership to application teams. Some have strong identity governance; others barely track privileged access. If the response process is fragmented, the SIEM will simply reflect that fragmentation in high resolution.
Before enabling data feeds, define:
- Who owns triage?
- What constitutes a high-severity alert?
- What response times are realistic?
- Where does automation fit without introducing risk?
The best practices for CrowdStrike NG-SIEM implementation begin with clarity on workflow. Technology should reinforce operational reality, not attempt to mask its gaps.
There is also a cultural aspect. Endpoint teams, cloud engineers and identity specialists often operate in silos. A unified SIEM can surface cross-domain patterns, but only if those teams accept shared visibility. Without that shift, data aggregation becomes little more than centralised logging.
Map Data Sources with Intent
It is tempting to ingest everything. Storage is elastic. Query engines are powerful. The marketing material implies limitless scalability.
In practice, indiscriminate ingestion creates blind spots. Analysts drown in low-value telemetry while genuinely suspicious signals get buried.
A more disciplined approach helps.
Begin by mapping data sources to specific detection goals. For example:
- Endpoint telemetry to detect lateral movement.
- Identity logs to flag impossible travel or privilege escalation.
- Cloud control plane events to catch misconfigurations and unauthorised changes.
- Email security signals to trace phishing-to-endpoint chains.
If a data stream does not support a defined detection or investigation use case, its inclusion should be questioned. That does not mean discarding it permanently. It means deferring ingestion until there is a reason to act on it.
CrowdStrike NG-SIEM benefits from tight integration with Falcon telemetry. That provides strong baseline visibility from endpoints. The gap often lies elsewhere, particularly in legacy infrastructure and third-party SaaS applications. Those integrations need deliberate validation. A connector that technically works but produces inconsistent fields is worse than no connector at all.
Design for Detection Engineering, Not Just Log Collection
A SIEM project can drift into infrastructure engineering. Pipelines, parsing rules, storage optimisation. All necessary, but insufficient.
Detection engineering requires time and attention. It also requires people who understand adversary behaviour rather than simply compliance requirements.
The best practices for CrowdStrike NG-SIEM Implementation include building detection logic around known attack paths. MITRE ATT&CK frameworks are useful references, but they should not be copied blindly. Real incidents offer better guidance. Ransomware campaigns, insider misuse, credential theft. Study how they unfold in your own environment.
Detection content should evolve. Static rule sets age quickly. As organisations move workloads to cloud-native architectures or adopt new identity providers, the threat surface shifts. The SIEM must track that shift.
This often means dedicating resources to continuous tuning. Not once a quarter. Not when an audit approaches. Regularly.
A Practical Implementation Flow
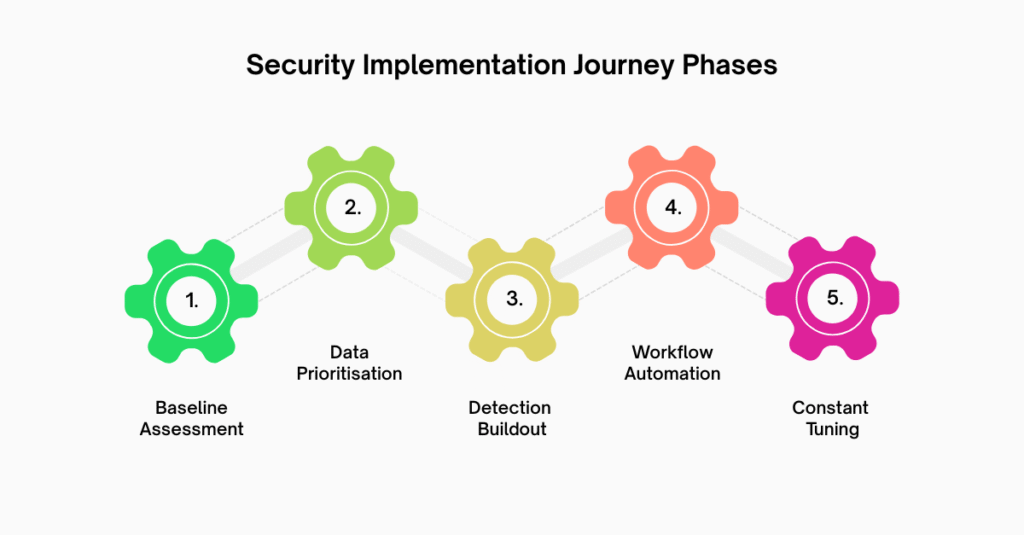
When preparing to visualise the implementation journey, it helps to anchor it in phases that reflect operational maturity rather than vendor milestones.
- Baseline Assessment
Evaluate existing logging, alert fatigue levels, and incident response maturity. Identify obvious telemetry gaps.
- Data Prioritisation and Integration
Onboard high-value sources first. Validate field mappings and normalisation. Confirm time synchronisation across systems.
- Initial Detection Buildout
Deploy core detection rules aligned to high-risk scenarios. Test them with simulated attack activity where possible.
- Workflow Alignment and Automation
Integrate with ticketing systems and case management. Introduce automation carefully, starting with enrichment rather than containment.
- Continuous Tuning and Expansion
Review alert quality weekly. Retire noisy rules. Add new logic based on emerging threats and internal changes.
Each phase should produce observable improvement in signal quality. If alert volumes spike without increased insight, something is misaligned.
This structured flow is not rigid. Some organisations may loop back to earlier phases after discovering unanticipated data quality issues. That is normal. Implementation rarely progresses in a straight line.
Address Performance and Cost Early
Even modern SIEM architectures encounter trade-offs. Query performance, retention periods and long-term storage all carry cost implications.
Leadership often assumes that cloud-native SIEM automatically solves the traditional scaling problem. It does not eliminate it. It changes its shape.
Retention policies should align with regulatory obligations and investigative needs. Storing a year of verbose debug logs may satisfy curiosity, but it will not necessarily strengthen security.
Performance tuning also matters for analyst efficiency. If queries take minutes to return during an active incident, frustration builds quickly. Analysts revert to isolated tools. The unified view fractures.
Plan capacity with realistic workload estimates. Factor in growth. Cloud adoption, remote work, and API integrations tend to increase log volume steadily. Few organisations see it decrease.
Integrate Identity as a First-Class Signal
Modern breaches rarely begin with exotic malware. They begin with compromised credentials.
Identity telemetry deserves equal prominence to endpoint data. That means ingesting authentication logs, privilege changes, federation events, and conditional access signals. It also means correlating them with device posture.
CrowdStrike’s ecosystem can tie identity risk to endpoint context. That correlation is powerful, but only if the underlying identity data is clean. Inconsistent naming conventions or unmanaged service accounts introduce ambiguity.
Many security teams underestimate the effort required to normalise identity data. The SIEM exposes those inconsistencies quickly. Treat that exposure as a governance opportunity rather than an inconvenience.
Test Under Pressure
Laboratory validation is not enough. Controlled simulations reveal gaps that routine monitoring misses.
Run tabletop exercises and technical simulations. Trigger detection rules intentionally. Observe escalation paths. Measure response times. Identify confusion points.
Often, the issue is not the rule itself but the clarity of the alert narrative. An analyst reading an alert at three in the morning should not need to cross-reference five dashboards to understand the risk.
Testing also reveals integration weaknesses. If automated containment fails silently, trust erodes. Confidence in the platform depends on predictability.
The best practices for CrowdStrike NG-SIEM Implementation therefore include regular adversary emulation exercises. Not as marketing demonstrations, but as operational rehearsals.
Avoid Over-Reliance on Default Content
Vendor-provided detection content offers a starting point. It reflects broad threat intelligence and collective experience.
However, default rules rarely account for the quirks of a specific environment. An organisation with heavy DevOps automation may trigger alerts that would be highly suspicious elsewhere. Conversely, a tightly controlled environment may require more aggressive thresholds.
Blind trust in default configurations creates complacency. Treat them as scaffolding. Gradually replace or refine them based on observed behaviour.
There is also a governance aspect. Document rule ownership. Assign accountability for review cycles. When nobody owns detection content, drift is inevitable.
Conclusion
The best practices for CrowdStrike NG-SIEM implementation are less about toggling features and more about aligning people, process, and telemetry. A SIEM can consolidate data, but it cannot repair fragmented operations or unclear accountability.
Organisations that succeed tend to invest in detection engineering, validate integrations carefully and treat tuning as ongoing work rather than a project phase. They test their assumptions under pressure. They accept that visibility without discipline simply creates louder noise.
For teams considering this journey, external perspective can be valuable. CyberNX can help you make the decision and help with CrowdStrike consulting. They can help you stream and analyse Falcon data with AI-driven SIEM. This will help you accelerate SOC efficiency, reduce noise and enable smarter threat response.
A well-implemented NG-SIEM does not just collect logs. It sharpens judgement. That difference becomes clear only when the next serious incident arrives.


